
Meta has publicly released LLaMA (Large Language Model Meta AI), a state-of-the-art foundational large language model designed to help researchers advance their work in this subfield of AI. Meta is making LLaMA available at several sizes (7B, 13B, 33B, and 65B parameters) and also sharing a LLaMA model card that details how they built the model in keeping with their approach to Responsible AI practices.
New project by Meta AI that focuses on training language models using a unique approach. With this approach, the New 65 billion parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses. It is called as 'LIMA'.
What is LIMA?
LIMA is an acronym for "Less Is More for Alignment". It is a system that demonstrates strong performance in learning to follow specific response formats from only a handful of examples in the training data. The main idea behind LIMA is to achieve better alignment by using fewer examples.
Innovative Training Approach
Lima's training approach involves two stages: unsupervised pre-training and fine-tuning with reinforcement learning. The authors of the paper aim to determine the relative importance of these two stages by training a 65 billion parameter language model called Lima. Lima is fine-tuned for only using a thousand carefully selected prompts and responses without any reinforcement learning or human preferences in terms of its modeling.
Data Collection Process
The training prompts were collected from three different community question and answer websites, including Stack Exchange, WikiHow, and Push Shift (utilizing Reddit datasets). Stack Exchange and WikiHow provided informative and helpful answers aligned with desired behavior of a helpful AI agent. Push Shift contained highly uploaded answers from Reddit which did not align well with desired behavior.
Training Process
Researchers followed a protocol starting with LAMA 65 billion model. A special token called EOT was created to distinguish between speakers during training process. EOT token facilitated more alignment and learning process when trying to differentiate between user and assistant utterances.
Lima Performance Evaluation
The performance evaluation of Lima is conducted with five different baselines. The purpose of this evaluation was to assess how well Lima performed in comparison to these different types of baselines such as gpt4 Claude and Etc.
The evaluation was conducted with 300 test prompts. Participants were presented with a test prompt as well as a response generated by Lima and the baselines.
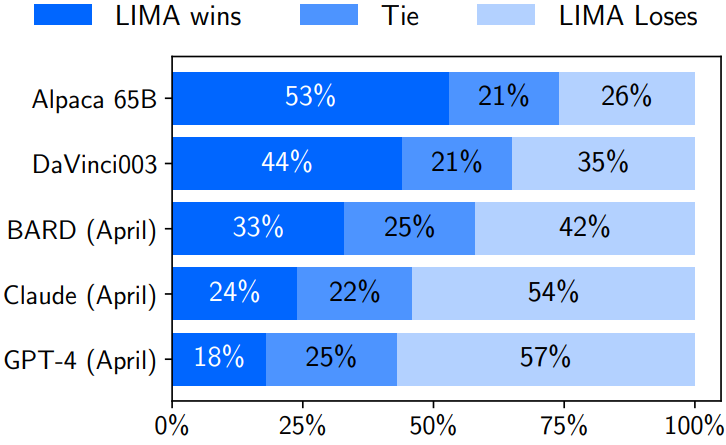
source - https://arxiv.org/pdf/2305.11206.pdf
The figure provides a visual representation of the evaluation's responses which showcases the percentage Inc of cases in which the responses from Lima were equivalent or actually preferred over these different types of baselines. Despite training significantly more data, Alpaca 65 billion parameter model tends to generate less preferable outputs compared to Lima. Similarly, DaVinci has been able to produce less preferable output from Lima.
Performance of Lima Language Model
The Lima language model was able to be on par with other models and even preferred in certain cases.
Fine-tuning with limited instruction data is sufficient to teach the model to produce high-quality outputs.
Pre-training enables the model to work on unseen tasks not present in training data.
The Lima language model was able to be on par with other models and even preferred in certain cases.
Fine-tuning with limited instruction data is sufficient to teach the model to produce high-quality outputs.
Pre-training enables the model to work on unseen tasks not present in training data.
Effects on Alignment Processing
Increasing the diversity of training prompts rather than simply increasing the quantity of data plays a crucial role in terms of improving alignment processing. Data quality tends to be better in terms of its alignment results.
There are several benefits of using Lima language model stated as below.
Versatile Responses
Despite being trained on only a thousand prompts, Lima demonstrates strong performances showcasing its ability to understand and follow specific response formats. The training prompts cover a wide range of different tasks including planning trip itineraries and speculating about alternative history.
Good Generalization
It exhibits good generalization in terms of its capabilities and performs well on unseen tasks that are not present in the actual training data.
Evaluation Results
A controlled human study showed that the responses generated from Lima were equivalent or preferred over other models such as GPT4 Bard and Da Vinci. The key findings of a project that created the Lima language model is that pre-training is important for enabling models to learn general purposes and perform well across various tasks.
How can I access or use it?
At present, information on how to access or use the LIMA language model is limited. For further details on how to access or use LIMA, it is recommended to visit Meta’s website or get in touch with them directly. Additionally, the research paper link can be found in the source section at the end of this article.
Conclusion
Versatile Responses
Despite being trained on only a thousand prompts, Lima demonstrates strong performances showcasing its ability to understand and follow specific response formats. The training prompts cover a wide range of different tasks including planning trip itineraries and speculating about alternative history.
Good Generalization
It exhibits good generalization in terms of its capabilities and performs well on unseen tasks that are not present in the actual training data.
Evaluation Results
A controlled human study showed that the responses generated from Lima were equivalent or preferred over other models such as GPT4 Bard and Da Vinci. The key findings of a project that created the Lima language model is that pre-training is important for enabling models to learn general purposes and perform well across various tasks.
How can I access or use it?
At present, information on how to access or use the LIMA language model is limited. For further details on how to access or use LIMA, it is recommended to visit Meta’s website or get in touch with them directly. Additionally, the research paper link can be found in the source section at the end of this article.
Conclusion
The LIMA language model marks a noteworthy breakthrough in the realm of AI and the processing of natural language. The studies carried out by Meta AI reveal that the principal wellspring of knowledge for large language models is pretraining, while only a minimal amount of fine-tuning data is required to generate output of exceptional quality. This discovery challenges the prevailing methodology of extensive and intricate fine-tuning procedures, hinting at the potential for a more streamlined approach.
source
https://arxiv.org/abs/2305.11206
https://arxiv.org/pdf/2305.11206.pdf
No comments:
Post a Comment