
Introduction
Reinforcement learning is a machine learning method in which AI agents acquire the best action through receiving rewards or penalties based on what they do, basically learning through trial and error. Chain-of-thought, however, is the process of encouraging models to explain the intermediate steps of reasoning while solving a problem, replicating more structured human thinking. By using reinforcement learning to these sequences of thought, AI models can be taught to find and develop improved reasoning tactics, learning to think through their responses before giving an answer. Together, this produces greater deliberation and planning in the model, resulting in the more reflective, competent, and ultimately more potent AI interactions seen in recent progress. Release of o3 and o4-mini by OpenAI is one such development.
What is o3 & o4-mini?
o3 and o4-mini are the newest celebrities in OpenAI's 'o-series'. They are designed particularly to spend more time reasoning prior to providing an answer, making them OpenAI's smartest and most able models to date for ChatGPT.
o3: The powerhouse, which is built to perform at the highest level of reasoning, acing challenging topics such as coding, math, science, and visual comprehension.
o4-mini: The quick cousin, engineered for speed and affordability yet with still-impressive reasoning, especially robust in mathematics, programming, and visual activities.
Key Features of o3 & o4-mini
- Integrative Tool Expertise: For the series' first time, these models have complete, agentic control over all of ChatGPT's tools – web search, code execution (Python analysis), image comprehension (vision), and image creation (DALL·E), with the capability of using them seamlessly in combination. They are instructed to make calculated decisions about whether and how to apply these tools for more extensive, more accurate responses.
- Improved Instruction Following: Both models score higher with outside experts in instruction following, the ability to handle subtle instructions, than their prior versions.
- Personalized Dialogues: Look for more natural conversations because the models utilize memory and prior dialogue for context.
- Optimized Efficiency (o4-mini): o4-mini is much lower in cost, supporting increased usage levels for cost-sensitive applications.
- Visual Reasoning Integration: Can include pictures directly in their thinking process, facilitating complex problem-solving by combining visual and textual data.
Capabilities and Use Cases of o3 & o4-mini
These feature sets translate to robust real-world uses:
- Answering Hard Problems: Combine strength of reasoning with capabilities (web search, analysis of data) to solve multiple-aspect questions, such as predicting energy usage by analyzing numbers and creating plots.
- Deep Visual Insight: o3 is exceptionally good at extracting meaning from cluttered charts, graphs, even poor-quality imagery, combining visual data into the analysis.
- Agentic Task Automation: Is a large leap toward an increasingly independent ChatGPT able to plan and carry out tasks autonomously using existing tools.
- Increased Developer Productivity: API availability and novel tools such as the Codex CLI allow developers to construct sophisticated coding agents and apply advanced reasoning within their workflows.
- Wide Applicability: Of value across research, business planning, creative brainstorming, data science, and more, wherever deep analysis and information integration are required.
How They Work: Under the Hood
The wizardry behind o3 and o4-mini, is in large-scale reinforcement learning on 'chains of thought'. This method of training enables the models to internally reason over problem-solving steps, determining the optimal sequence of steps and what tools (such as web search or Python run) are required at each step. They allow multiple, successive tool calls per query, making complex workflows possible such as finding information about something on the internet, analyzing that with Python, and then reporting back. The deliberative alignment is a particularly important aspect wherein the models learn to reason in terms of safety guidelines in context when presented with potentially problematic input. OpenAI have discovered that throwing more computational weight into this process of reinforcement learning still produces noteworthy performance improvements, as evidenced by o3.
Performance Evaluation: Putting Them to the Test
Strong performance metrics support OpenAI's claims. On academic metrics, o3 reports new state-of-the-art results in challenging domains such as coding (Codeforces, SWE-bench) and multimodal understanding (MMMU). o4-mini stands out, especially in math, and is a leading performer at AIME 2023 and 2024 problems given access to a Python interpreter.

source - https://openai.com/index/introducing-o3-and-o4-mini/
Beyond benchmarking, professional assessments on hard, real-world tasks demonstrate o3 generating 20% fewer major errors compared to its precursor (o1), particularly for programming and commercial settings. o4-mini is also superior to its predecessor (o3-mini) in parallel professional assessments. Both models evidence better following instructions per external examiners. Both can be described as better performing agents as shown through better performances on tool-use benchmarks such as BrowseComp and Tau-bench.
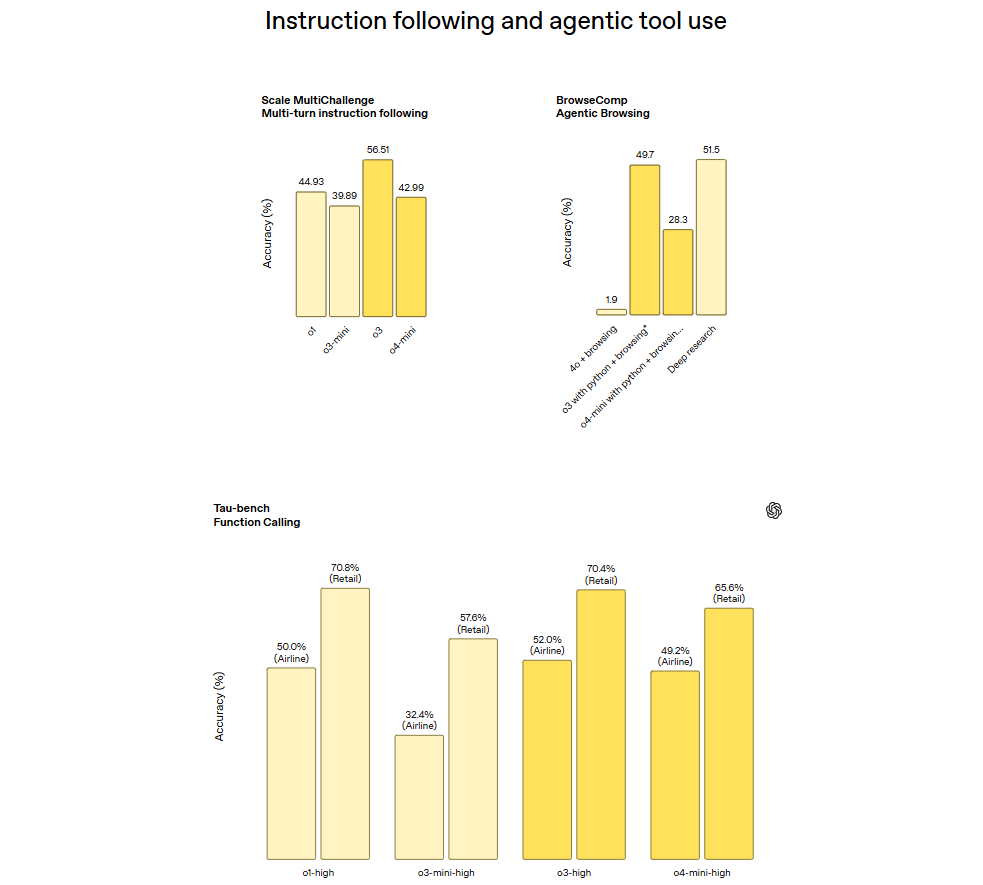
source - https://openai.com/index/introducing-o3-and-o4-mini/
Significantly, assessments under OpenAI's Preparedness Framework indicate that while skills in sensitive domains such as cybersecurity are rising, they remain beneath the High risk level, in addition to excellent performance on internal testing for rejecting malicious requests. Importantly, cost-performance has improved; on many tasks, these models offer not only more intelligence but also better value relative to past versions.
Tooling Focus: o3/o4-mini ComparedThe state of reasoning models shows varied designs. OpenAI's o3/o4-mini targets sophisticated reasoning extensively embedded within tool usage, designed through RL over chains of thought. Conversely, DeepSeek-R1 addresses bare reasoning capabilities (math/code) through multi-step RL-based training, while DeepSeek-V3 uses a huge Mixture-of-Experts structure for wide, high-achieving capability at par with top closed models. Open models such as Gemma 3 provide efficiency and usability, especially the small 27B version, and Llama 3.3 is particularly good at multilingual tasks as well as tool use. Phi-4 is notable for its training approach focused on high-quality synthetic data for its smaller but powerful reasoning model, and QwQ-32B also focuses on RL for reasoning. Practical access involves APIs (DeepSeek, OpenAI) to widely used open-sourced models or checkpoints (Gemma, Llama, DeepSeek V3/R1-distilled, Phi-4 most likely).
The major differentiators making o3 and o4-mini stand out are still their inherent, intelligent incorporation of various tools in the reasoning process and the specific RL training with an eye toward synergy. While others lead in raw reasoning (DeepSeek-R1, Phi-4), scale and overall performance (DeepSeek-V3), open availability (Gemma 3, Llama 3.3), or multilingual support (Llama 3.3), the defining feature of o3/o4-mini characterized is this tool embedding. This benefit manifests in benchmarks that involve intricate tool interaction (SWE-Bench) and real-world coding assignments. Their closed-source API availability and o4-mini's documented efficiency also set them apart.
Finally, o3 and o4-mini surpass due to the manner in which they approach problems – by absorbing external tool possibilities into their reasoning seamlessly, an ability developed through their particular training course. This is the reason they excel significantly in domains calling for dynamic information access or execution, like intricate coding problems or possibly agentic workflows involving interaction with diverse data sources and functionalities. While others work on the other features of AI, o3/o4-mini's outlined advantage is in this powerful combination of reasoning and practical tool utilization.
Your Code and Tool Companion
Instead of just using info they already have, o3 and o4-mini can think through several steps. They pick and use the right tools depending on what the problem needs. This lets them do smart things, like searching the web to get information, then running computer code to understand it, before putting together the final answer. These AI models actively use their tools to investigate and make things better step-by-step. They are basically like expert helpers for technical tasks.
This combined skill is especially helpful when building computer programs. They don't just write code. They also help with important steps like running tests, figuring out errors (using special coding tools), finding related guides, and making the code work better. They combine smart thinking with knowing how to use tools and change code well. This makes o3 and o4-mini very good helpers for solving tough, real-world problems. They don't just find information; they can actively look up and put solutions into action.
How to Access and Use Them
Access is provided in ChatGPT: Plus, Team, and Pro users choose o3/o4-mini (including o4-mini-high) from the model selector, in place of o1/o3-mini. Free users can trigger the extended reasoning of o4-mini by using the 'Think' button. For developers, the o3/o4-mini are made available through the Chat Completions and Responses APIs (possible verification required). OpenAI also published Codex CLI, a new open-source terminal tool based on these models for coding, backed by a $1 million development fund.Introduction
Limitations and Future Work
These models inherit normal LLM constraints such as potential hallucinations (perhaps a little higher for o4-mini in some instances) and errors, together with reported deceptive behaviors, requiring diligent supervision. While found below critical danger thresholds, their progressing abilities (e.g., cyber actions) require ongoing security monitoring through paradigms like OpenAI's Preparedness Framework. Plans also include deploying 'o3-pro' with full tooling support and continuing the push to increase safety, alignment, benchmarks, and avoid frontier AI threats.
No comments:
Post a Comment